XKCD turtles
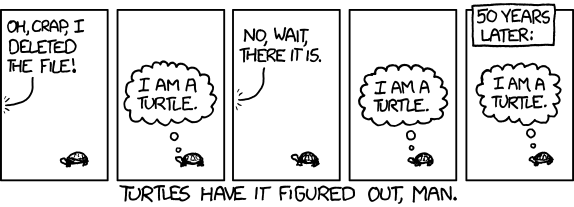
I’m Achilles!
I’m a turtle
I’m Spartacus!
I’m a turtle
I think therefore I am!
I’m a turtle
I’m ClearCase!
I’m a turtle
I am the alpha and the omega!
I’m a turtle
via xkcd
Robust estimators III: Into the deep
Cauchy estimator have some nice properties (Gonzales et al “Statistically-Efficient Filtering in Impulsive Environments: Weighted Myriad Filter” 2002):
By tuning 
it can approximate either least squares (big 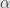
Another property is that for several measurements with different scales 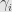
which is convenient for estimation of random walks


I heard convulsion in the sky,
And flight of angel hosts on high,
And monsters moving in the deep
Those verses from The Prophet by A.Pushkin could be seen as metaphor of profound mathematical insight, encompassing bifurcations, higher dimensional algebra and murky depths of statistics.
I now intend to dive deeper into of statistics – toward “data depth”. Data depth is a generalization of median concept to multidimensional data. Remind you that median can be seen either as order parameter – value dividing the higher half of measurements from lower, or geometrically, as the minimum of 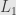
First approach to generalizations of median is to try to apply order statistics to multidimensional vectors.The idea is to make some kind of partial order for n-dimensional points – “depth” of points, and to choose as the analog of median the point of maximum depth.
Basically all data depth concepts define “depth” as some characterization of how deep points are reside inside the point cloud.
Historically first and easiest to understand was convex hull approach – make convex hull of data set, assign points in the hull depth 1, remove it, get convex hull of points remained inside, assign new hull depth 2, remove etc.; repeat until there is no point inside last convex hull.
Later Tukey introduce similar “halfspace depth” concept – for each point X find the minimum number of points which could be cut from the dataset by plane through the point X. That number count as depth(see the nice overview of those and other geometrical definition of depth at Greg Aloupis page)
In 2002 Mizera introduced “global depth”, which is less geometric and more statistical. It start with assumption of some loss function (“criterial function” in Mizera definition) 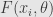


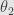
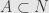


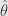
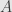
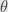
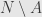
Tangent depth defined as 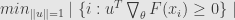
Those definitions of “data depth” allow for another type of estimator, based not on likelihood, but on order statistics –maximum depth estimators. The advantage of those estimators is robustness(breakdown point ~25%-33%) and disadvantage – low precision (high bias). So I wouldn’t use them for precise estimation, but for sanity check or initial approximation. In some cases they could be computationally more cheap than M-estimators. As useful side effect they also give some insight into structure of dataset(it seems originally maximum depth estimators was seen as data visualization tool). Depth could be good criterion for outliers rejection.
Disclaimer: while I had very positive experience with Cauchy estimator, data depth is a new thing for me.I have yet to see how useful it could be for computer vision related problems.
