Interior point method – if all you have is a hammer
Interior point method for nonlinear optimization often considered as complex, or highly nontrivial etc. The fact is, that for “simple” nonlinear optimization it’s quite simple, manageable and can even be explained in #3tweets. For those not familiar with it there is a simple introduction to it in wikipedia, which in turn follows an excellent paper by Margaret H. Wright.
Now about “if all you have is a hammer, everything looks like a nail”. Some of applications of interior point method could be quite unexpected.
Everyone who worked with Levenberg-Marquardt minimization algorithm know how much pain is the choice of the small parameter 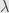
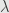
Interior point can help here.
If we choose shape of trust region for Gauss-Newton as hypercube or simplex or like, we can formulate it as set of L1 norm inequality constrains. And that is the domain of interior point method! For hypercube 
W – hessian, I – identity, diag – diagonal
That is a banded arrowhead matrix, and for it Cholesky decomposition cost insignificantly more than decomposition of original W. The matrix is not positive definite – Cholesky without square root should be used.
Now there is a temptation to use single constrain 
The same method could be used whenever we have to put constrain on the value of Gauss-Newton update, and shape of constrain in not important (or polygonal)
Now last touch – Interior point method has small parameter of it’s own. It’s called usually 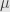


In our case (IPM for trust region) we don’t need update