Split Bregamn method is one of the most used method for solving convex optimization problem with non-smooth regularization. Mostly it used for 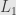 regularization, and here I want to talk about TV-L1 and similar regularizers ( like
regularization, and here I want to talk about TV-L1 and similar regularizers ( like  )
)
For simplest possible one-dimentional denoising case
 (1)
(1)
Split Bregman iteration looks like
 (2)
(2)
 (3)
(3)
 (4)
(4)
There is a lot of literature about choosing 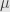 parameter from (1) for denosing. Methods include Morozov discrepancy principle, L-curve and more – that’s just parameter of Tikhonov regularization.
parameter from (1) for denosing. Methods include Morozov discrepancy principle, L-curve and more – that’s just parameter of Tikhonov regularization.
There is a lot less metods for choosing 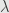 for Split Bregman.
for Split Bregman.
Theoretically shouldn’t be very important – if Split Bregman converge solution is not depending on . In practice of cause convergence speed and stability depend on a lot. Here I’ll point out some simple consideration which may help to choose
Assume for simplicity that u is twice differentiable almoste everythere, the (1) become
 (5)
(5)
We know if Split Bbregman converge 
that mean  , here exteranl derivative is a weak derivative.
, here exteranl derivative is a weak derivative.
For the solution b is therefore locally constant, and we even know what constant it is.
Recalling

For  we have
we have
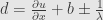
and accordingly
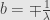
For converged solution

everythere where  is not zero, with possible exeption of measure zero set.
is not zero, with possible exeption of measure zero set.
Now returning to choice of for Split Bregman iterations.
From (4) we see that for small values b , b grow with step until it reach it’s maximum absolute value 
Also if the b is “wrong”, if we want for it to switch value in one iteration  should be more than
should be more than 
That give us lower boundary for :
For most of x 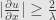
What happens if on some interval b reach  for two consequtive iterations?
for two consequtive iterations?
Then on the next iteration form (5) and (3) on that interval
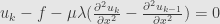
or

See taht with  big enuogh sign of
big enuogh sign of  stabilizing with high probaility and we could be close to true solution. The “could” in the last sentence is there because we are inside the interval, and if the values of u on the ends of interval are wrong b “flipping” can propagate inside our interval.
stabilizing with high probaility and we could be close to true solution. The “could” in the last sentence is there because we are inside the interval, and if the values of u on the ends of interval are wrong b “flipping” can propagate inside our interval.
It’s more difficult to estimate upper boundary for .
Obviously for more easy solution of (2) or (5) shouldn’t be too big, so that eigenvalues of operator 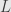 woudn’t be too close to 1. Because solutions of (2) are inexact in Split Breagman we obviously want having bigger eigenvalues, so that single (or small number of) iteration could suppress error good enough for (2) subproblem.
woudn’t be too close to 1. Because solutions of (2) are inexact in Split Breagman we obviously want having bigger eigenvalues, so that single (or small number of) iteration could suppress error good enough for (2) subproblem.
So in conclusion (and my limited experience) if you can estimate 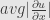 for solution
for solution  could be a good value to start testing.
could be a good value to start testing.
2, January, 2013
Posted by mirror2image |
computer vision |
2 Comments
